Présentation du Pipeline
Notre pipeline transforme les documents d’analyses médicales en rapports structurés et interprétés. L’architecture se divise en 4 parties principales, permettant un traitement progressif des données.
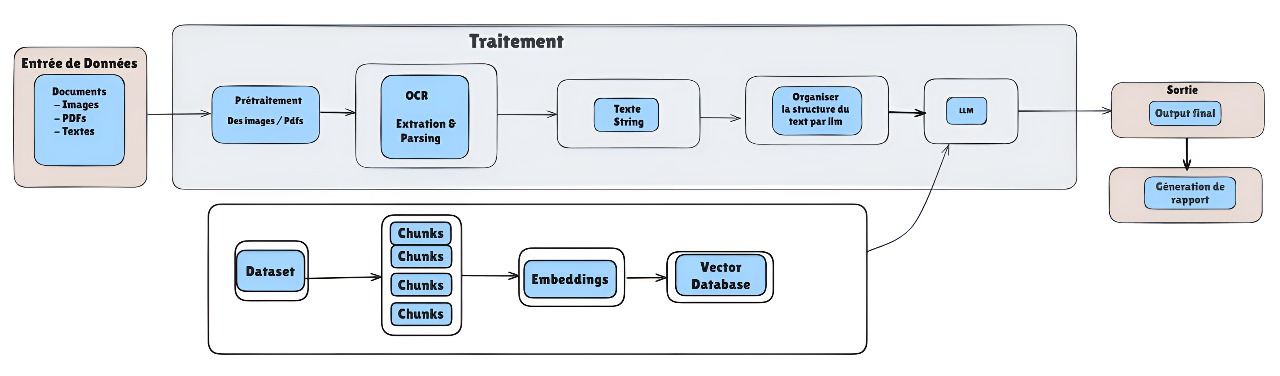
Notre pipeline de traitement des analyses médicales
Entrée & Prétraitement
Les documents entrent sous trois formes : - Images scannées - PDFs - Fichiers texte
Le prétraitement prépare ces documents pour l’extraction : normalisation, correction d’orientation, amélioration de la qualité quand nécessaire.
Traitement Principal
OCR & Extraction
L’OCR transforme les documents en texte exploitable. Cette étape est critique - la qualité de l’extraction impacte toute la suite du processus.
Organisation du Texte
Le texte brut est structuré en sections logiques : - Identification des paramètres - Repérage des valeurs et unités - Regroupement par catégories d’analyses
LLM & Analyse
Le modèle de langage analyse les données structurées pour : - Comprendre le contexte médical - Repérer les anomalies - Préparer l’interprétation
Base de Connaissances
Le système s’appuie sur une base de connaissances médicales : - Dataset médical - Chunks pour le découpage intelligent - Embeddings pour la représentation vectorielle - Base de données vectorielle pour la recherche rapide
Génération des Résultats
Le pipeline produit deux sorties : - Un output structuré pour le traitement informatique - Un rapport médical formaté pour les praticiens
Points Techniques Essentiels
Architecture modulaire pour faciliter les mises à jour
Validation à chaque étape du processus
Traçabilité complète du traitement
Performance optimisée sur les étapes critiques